


Published on MarTech Series
Read on Screen6.io
Let’s try to agree on what is black and white…
There is a lot of noise in the industry about the selection of cross-device solutions. However, with all the conversation surrounding omni channel marketing, there is a significant gap in the understanding of the underlying technology.
While many platforms in the space are running head to head tests to compare match rates, precision, etc. – there is very little differentiation between the usual vendors. All of them fall into a category which we refer to as “Master Device Graph” companies, where data is co-mingled from various sources, including the client’s data, and built into a single output which is licensed over and over – in essence, becoming a commodity.
As such, there have been recent attempts to standardize the method of verification of cross-device graphs by the vendors themselves as well as by third-parties. However, by formalizing the specific process by which agencies, marketing platforms (both on the buy and sell side), data providers, and the like engage with and compare vendors to a list of binary questions (i.e. How large is your desktop cookie pool?) they are limiting their own as well as the industry’s perspective on what a sound solution looks like and how it performs. Instead of innovating, they are aiming to check off pre-determined boxes. This will not lead to the right solution, but to the solution which is already categorized as best for a problem already solved – or at least based on a low acceptable standard.

It seems like all players in the market these days understand the shortcomings of a single, Master Device Graph as Drawbridge’s Bhumika Dadbhawala articulates clearly in an article titled, “Build, Buy Or Die? The Existential Question Of Cross-Device Identity,” published on MediaPost. Dadbhawala explains the advantages of private device graphs, “When the data and bidder are part of one platform, the data is built on the exact inventory being used in the platform, and thus more efficient”.
Another potential issue with these commoditized graphs – as noted in a recent AdExchanger article by James Hercher – is that the deterministic data to build (part of) these graphs is flawed: “Many cross-device vendors and data aggregators regularly pay publishers to help them connect a customer’s data to web traffic or email sign-ups. The inconsistencies plaguing publisher data monetization – bot farms juicing numbers with fake emails or actual people using throwaway addresses on non-billing accounts – can be passed on to device graphs.”

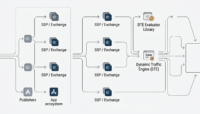
Regardless of the exact methodology used to build cross-device associations, Screen6 would like to present an easily comprehendible way to validate the results. The following infographic walks through how a platform can verify the precision of a graph delivered by a third-party – not just Screen6 – against a Verification Dataset.
“Important terminology is defined differently by different parties in the cross-device ecosystem and buyers don’t often know how to ask the questions that will prompt relevant responses for their individual use-cases and desired outcomes,” shared Philipp Tsipman, VP of ConnectedID at MediaMath, with the Data & Marketing Association.
While we would personally debate the usefulness of a standardized RFI for a new and less-understood technology, we agree that unifying the terminology and verification techniques across an industry for all types of solutions will bring clarity to a vertical otherwise riddled with acronyms and misnomers.