


Published on MediaPost
Read on Screen6.io
Data has unquestionably made digital marketing more accurate and personal to the user experience, but there is an important problem that exists across the data spectrum. Not all data is created equal and data distrust occurs when we begin to question the quality of data we use. In a recent KPMG study, 84% of CEOs indicated they’re concerned about the quality of the data they’re basing their decisions on.
Almost 10 million Americans have changed how they identify their own race or ethnicity when asked by the Census Bureau over the course of a decade, clearly underscoring the uncertainty of data that the industry once considered to be reliable.
The fallacy of accurate self-identified data is all around us. How many of us of have logged onto the internet at a hotel and put in John@Smith.com? It’s the same when consumers fill out forms with bogus information — fake names and phone numbers and, most commonly, putting in a fake zip code.
Only 65,936 people live in Schenectady, N.Y. Why is that number important? The zip code for Schenectady is 12345. And how many times have you used 12345 as your zip code?
It is a false notion that deterministic data and observed, self-identified data are almost always accurate. In fact, there is a high likelihood that self-declared data from a consumer is inaccurate, whether that is because they misrepresent themselves, because they have skewed perceptions of themselves, they are protecting their privacy or because they’re just lying for the sake of lying.
And the problem isn’t confined to self-identifying data. The geographic center of the United States is in Lebanon, Kan. When services that map a device’s Internet Protocol address don’t know where someone using a website is located, they point to the front yard of a farm in Kansas. When we have 10,000 data points identified within 1 square meter of where a server is hosted but still utilize this information in the decision-making process, we have a problem.
Neither deterministic or probabilistic is perfect. However, you can’t rely solely on either one. Rather, you need to think carefully about how you validate the data that is provided to you. For example, if you don’t validate location data that seems a bit strange, you are going to end up with centroids within the U.S. or within a specific state.
With over 85% of all goods purchased within 10 miles of the home, it is easy to understand why there is significant interest in localized geo-targeting. But without verification and validation of data, any advertising buy could be off by miles, possibly by an entire state. Companies that can deliver more accurate targeting and audience identification will inevitably take a larger piece of the pie.
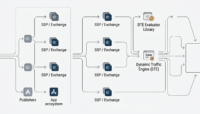
We think constantly about how we use data to make advertising more effective for buyers, sellers and consumers. But all too often, marketers use brute force tactics to deliver, serve, and retarget ads. The experience of finding a consumer to deliver a relevant, targeted ad to isn’t as seamless and integrated as we’d often like.
Marketers want accurate audience identification and consumer data in addition to a rock-solid, proven way to identify and recognize those potential customers as they move throughout their digital day — from screen to screen, mobile device to laptop, and then back to a tablet. True audience identification requires that marketers both validate and verify the data they are working with.
Smart marketers require technology that measures reach and frequency comprehensively, provides insights into cross-device attribution, and allows for targeting at scale, and frequency cap across channels. A cross-device ID for understanding individuals and not separate devices is no longer a nice-to-have — it is table stakes.
When it comes to the data used for identification and mapping, accuracy counts.